CVPR2018で気になった論文の抜粋
wifiの電波強度から姿勢推定
https://cvpaperchallenge.github.io/CVPR2018_Survey/#/Through-Wall_Human_Pose_Estimation_Using_Radio_Signals
RGBから3D姿勢推定
#イベントの検出と分割
繰り返しの動作を推定
ゲームからのレンダリング手法
https://cvpaperchallenge.github.io/CVPR2018_Survey/#/Free_supervision_from_video_games
異常検知
距離画像推定
3次元推定の比較実験
2D画像に移っている人物を色々な姿勢に変形!めっちゃ面白い!
どっちの技能が優れているか!めっちゃ近い分野!!
動画から,アフォーダンス取得だけど,まだまだって感じ
2Dからの3次元姿勢推定
長期のモーション推定
動画から対象と同じアクションを探す
動画の行動のラベル・開始と終了を推定する
※ねじ締め,配線,といった単位で分割できるようになると面白いかも
動画から人物の3次元姿勢推定
https://cvpaperchallenge.github.io/CVPR2018_Survey/#/Video_Based_Reconstruction_of_3D_People_Models
動画から行動推定
cvpr2018 challengeの気になった論文メモ
#6異常検知
https://cvpaperchallenge.github.io/CVPR2018_Survey/#/6
https://arxiv.org/pdf/1802.09088.pdf
https://cvpaperchallenge.github.io/CVPR2018_Survey/#/73
#群衆内の人物検知
https://cvpaperchallenge.github.io/CVPR2018_Survey/#/23
#点群の処理
https://cvpaperchallenge.github.io/CVPR2018_Survey/#/58
https://arxiv.org/pdf/1802.08275.pdf
https://arxiv.org/pdf/1503.04949.pdf←Bilateral Convolution Layer
#人物の検出だけでは終わらなく,物体の位置関係からなんの作業を行っているかを推定
https://cvpaperchallenge.github.io/CVPR2018_Survey/#/67
深層学習-まとめ
物体認識系
検出系
Keras implementation of RetinaNet object detection https://t.co/32lD95PzGB pic.twitter.com/xtliGyDaai
— Deep Hub (@Deep_Hub) 2018年3月10日
YOLOv3: An Incremental Improvement (ワシントン大) https://t.co/dC56ih5tvX 説明不要に面白いのでぜひ一読を.v3で加えた改善点&試したけど上手く行かなかったことの報告.同程度の性能のRetinaNetより3.8倍高速に物体認識.youtube https://t.co/oDdOB9eQVF code https://t.co/8xpJ5sjFMt pic.twitter.com/jAaKoCqXHZ
— Kyosuke Nishida (@kyoun) 2018年3月26日
#代表例
セグメンテーション系
Google、画像をピクセル単位で把握し各オブジェクトに割り当てるセマンティックセグメンテーションCNNモデル「DeepLab-v3」オープンソース発表 https://t.co/jEYVXavxmL pic.twitter.com/Y5gu97dxOz
— Seamless (@shiropen2) 2018年3月13日
姿勢推定
Facebook AI Researchら、密集した人間の姿勢を2D画像から推定し、人の表面にテクスチャマッピングできるCNNを用いたシステム「DensePose」を発表 https://t.co/0RK1xNovYs pic.twitter.com/0ZCuFMNmaA
— Seamless (@shiropen2) 2018年2月5日
手領域はロボット操作に活用してデモンストレーションを実行する。アーキテクチャでは、主に姿勢推定、3次元への投影(VoxelPoseNet)、手領域の法線ベクトル推定(HandNormalNet)から構成される。姿勢推定はOpenPoseを活用、VoxelPoseNetは3次元のL2ノルム誤差により計算する。 https://t.co/rzfkLxTnfd
— cvpaper.challenge (@CVpaperChalleng) 2018年3月15日
トラッキング系
Social GAN (Stanford) https://t.co/GRcp4R4QT4 複数人の移動軌跡の予測.物理的には尤もらしくても社会的におかしい(ぶつかる等)軌跡の予測を避ける.生成器をEncoder-PoolingModule(PM)-Decoderの構成として,PMで複数人の相互作用を考慮.PMはEncodingされた各人の状態と他人と相対位置を利用 pic.twitter.com/aRSJmqdSz9
— Kyosuke Nishida (@kyoun) 2018年3月30日
マルチモーダル系
Learning a Text-Video Embedding from Incomplete and Heterogeneous Data (ENS) https://t.co/bqljM2xJfl テキストと動画の同空間埋込.動画の画像,動き,顔,音声をマルチモーダルに考慮.全モーダルが揃ってないデータからも学習可.コード https://t.co/SdwRVfXrcA デモ https://t.co/zsSI4PqgeS pic.twitter.com/1PHpGfjwfE
— Kyosuke Nishida (@kyoun) 2018年4月10日
文字認識系
Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentation (Huazhong大) https://t.co/knpZMwq4MZ シーン画像からのテキスト抽出.テキスト領域の4コーナーの点および領域を個別に予測.抽出点をグルーピングして候補領域のスコア算出.COCO-Textや多言語のMLTで良い精度 pic.twitter.com/M0KelhxYUC
— Kyosuke Nishida (@kyoun) 2018年4月21日
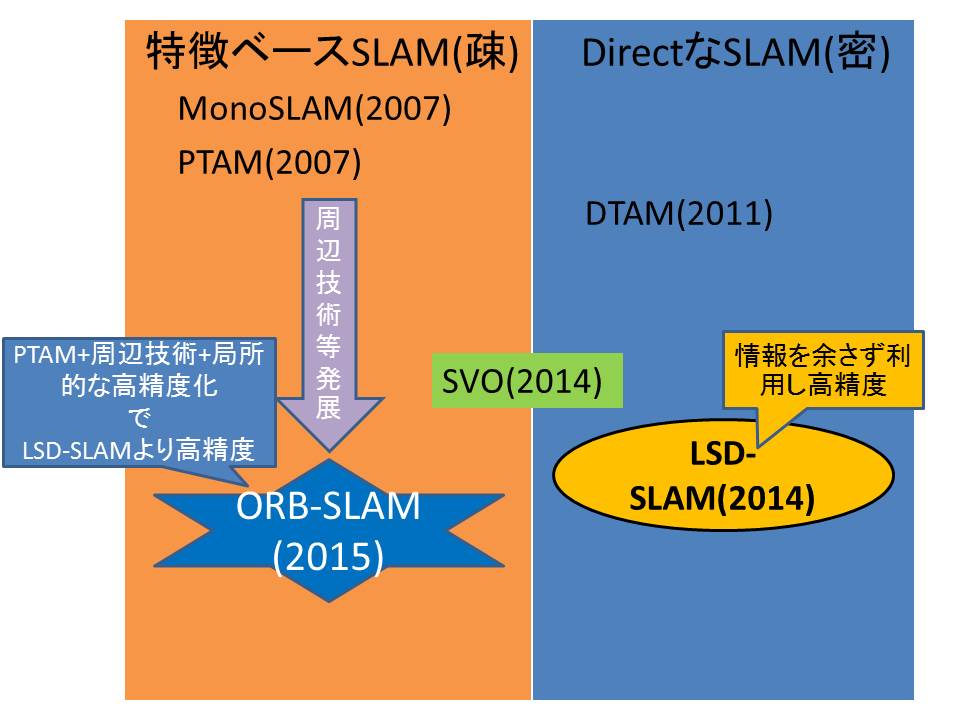
visual slam調査
気になったツイートからSLAM周りを色々調べてみた
以下のサイトでまぁ色々流し見してみた.
SLAMっていったらLRFのイメージで終わっていましたが, 最近は単眼カメラでのSLAMがアツイようですね.
(一番驚いたのは,Google翻訳の精度の高さでしたw)
VisualSLAMについて、歴史や有名研究室の概観から始まり、2016年(執筆時)までの流れがめちゃくちゃ良くまとまっている。原文中国語だけど、ブラウザで英語に翻訳すれば普通に読める。 https://t.co/e84X37h8hs
— Shintaro Shiba/芝 慎太朗 (@s_24_) 2018年3月2日
Visual SLAMで一番著名なAndrew Davisonさんのホームページ
周りがステレオ視でやるのが当たり前だという風潮のなか,単眼でも出来るぜ!って証明しちゃったすごい人らしい
https://www.doc.ic.ac.uk/~ajd/index.html←ホームページ
http://wp.doc.ic.ac.uk/thefutureofslam/wp-content/uploads/sites/93/2015/12/slides_ajd.pdf←VSLAMの15年についてのスライド
https://www.doc.ic.ac.uk/~ajd/Publications/davison_etal_pami2007.pdf ←著名な論文Mono SLAM
各Visual SLAMの説明
以下のスライドに紹介されてる
https://www.doc.ic.ac.uk/~ajd/Scene/Release/monoslamtutorial.pdf
ORB-SLAM
ptamをベースにあれこれ改良したものらしい.
CNN-SLAM
年表的なもの